
Dane badawcze – dane wytworzone lub zebrane podczas i na potrzeby badań naukowych. Mogą być wyrażone w następującej postaci: dane liczbowe, dokumenty tekstowe/notatki/obrazy, kwestionariusze i/lub ankiety, nagrania audio/video, zawartość baz danych, modele matematyczne, algorytmy, oprogramowanie (skrypty/pliki wejściowe), wyniki symulacji komputerowych, protokoły laboratoryjne, opisy metodologiczne.
Dane badawcze (inne definicje):
- Dane zebrane, zaobserwowane lub wytworzone jako materiał do analizy, w celu uzyskania oryginalnych wyników naukowych.
- Wszystko co zostało wyprodukowane lub wytworzone w ramach prowadzonych badań.
Otwarte dane badawcze – wg Panton Principles, rozumiane jako swobodny dostęp w ogólnodostępnym Internecie, umożliwiający każdemu użytkownikowi pobieranie, kopiowanie, analizowanie, przetwarzanie, przekazywanie (za pomocą oprogramowania) lub używanie pozyskanych danych w jakimkolwiek innym celu bez barier finansowych, prawnych lub technicznych.
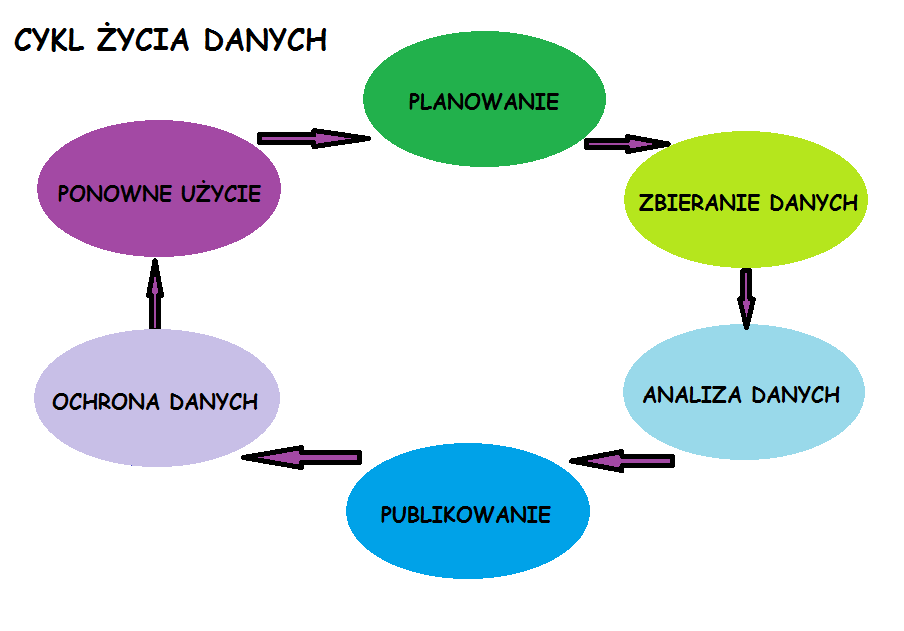
Zasady FAIR:
Skrót FAIR to akronim 4 angielskich przymiotników opisujących, to jakie dane badawcze powinny być.
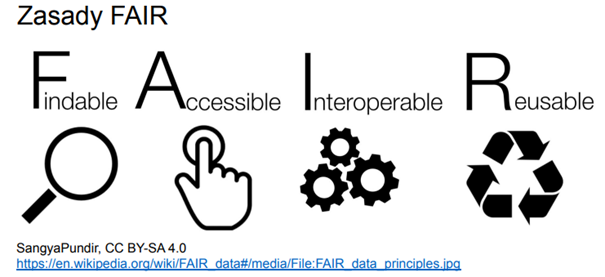
- Findable – możliwe do odnalezienia;
- Accessible – dostępne;
- Interoperable – interoperacyjne, rozumiane jako połączenie danych z innymi zbiorami pochodzącymi z innych źródeł;
- Reusable – możliwe do ponownego użycia.
Zasady FAIR – przydatne informacje:
- Polityka Komisji Europejskiej (KE), Horyzont Europa (zasady FAIR uwzględnione w DMP);
- Wytyczne Narodowego Centrum Nauki (NCN) do sporządzania DMP;
- Dyrektywa ws. otwartych danych i ponownego wykorzystania informacji sektora publicznego;
- Narzędzia: FAIR self assessment tool – ARDC FAIR Aware: https://fairaware.dans.knaw.nl/
Repozytorium danych – miejsce deponowania (umieszczania) i przechowywania danych w formie cyfrowej. Charakterystyka: bezpieczne długoterminowe przechowywanie, stały adres internetowy, możliwość uzyskania stałego identyfikatora (DOI), łatwość wyszukiwania, podstawowe statystyki (informacje o tym jak często dane były pobierane/oglądane), łatwość cytowania.
Repozytorium danych – dlaczego warto?
- Zapewnienie trwałych i niepowtarzalnych identyfikatorów (PID);
- Metadane: zapewnienie skutecznego wyszukiwania danych; umożliwienie odniesień do powiązanych istotnych informacji (tj. inne dane i publikacje); udostępnienie informacji, które są publicznie dostępne i których zasoby są utrzymywane, nawet w przypadku niepublikowanych, chronionych, wycofanych lub usuniętych danych;
- Dostęp do danych i warunki licencji użytkowania: umożliwienie dostępu do danych w ściśle określonych warunkach; zapewnienie autentyczności, integralności danych i możliwości pobierania danych; udzielenie informacji na temat warunków licencjonowania i udzielania pozwoleń (odczyt maszynowy/automatyzacja procesu); zapewnienie poufności i poszanowanie praw twórców i osób których dane dotyczą;
- Zachowanie danych: zapewnienie trwałości metadanych i danych; zachowanie przejrzystości w zakresie misji, zakresu i zasad ochrony danych.
RepOD – Repozytorium Otwartych Danych https://repod.icm.edu.pl/
- Czym jest i dla kogo jest przeznaczony?
Repozytorium Otwartych Danych RepOD – to repozytorium ogólnego przeznaczenia służące do otwartego udostępniania wszelkiego typu danych badawczych wytworzonych, zebranych albo opisanych na potrzeby działalności naukowej. Mogą z niego korzystać wszyscy badacze, bez względu na afiliacje i dyscypliny, oraz instytucje naukowe zainteresowane utworzeniem własnych kolekcji.
Uniwersytet Szczeciński posiada w RepODzie swoją kolekcję instytucjonalną.
Jak korzystać z repozytorium?
Krok 1: założenie konta
- Wchodzimy na stronę: https://repod.icm.edu.pl/
- W przypadku pierwszej wizyty na stronie należy założyć konto (Załóż konto, górny prawy róg strony) lub zalogować się na wcześniej założone konto (Zaloguj).
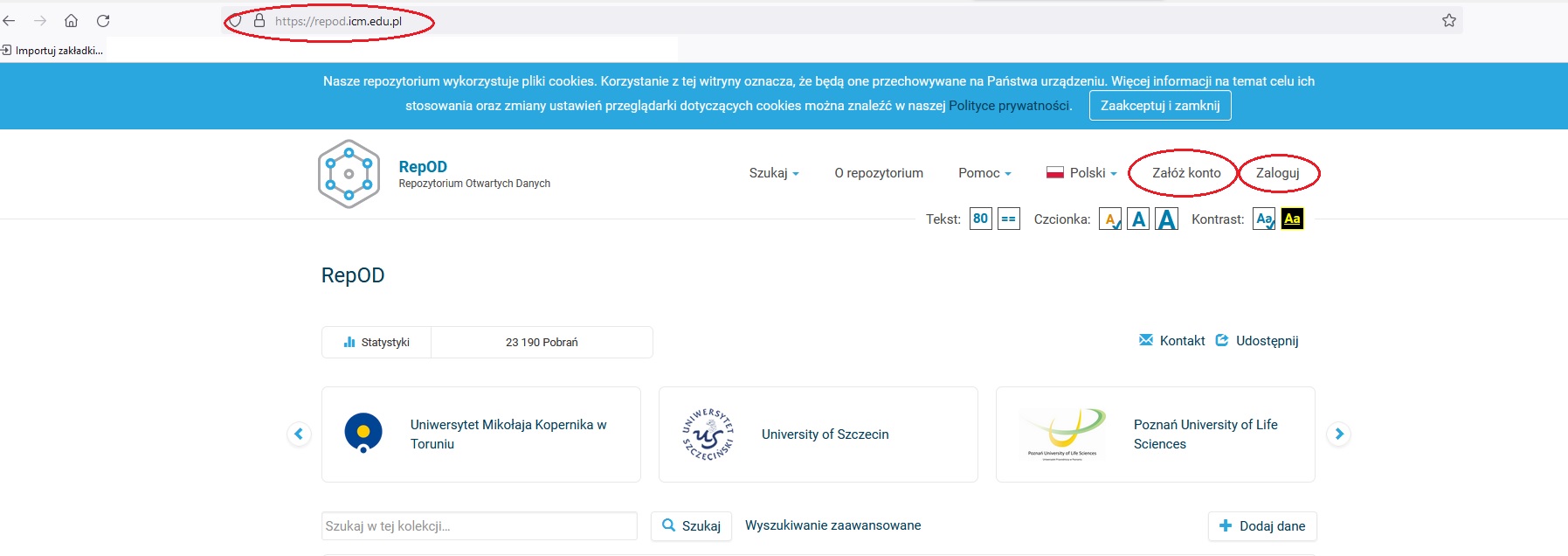
- Ważne: prosimy zakładać konto i logować się tylko i wyłącznie z uczelnianej poczty imie.nazwisko@usz.edu.pl (tylko wtedy Państwa dane trafią do kolekcji danych Uniwersytetu Szczecińskiego).
- Przy zakładaniu konta prosimy wypełnić następujące pola: dane użytkownika, hasło, zaznaczyć wszystkie zgody i utworzyć konto.
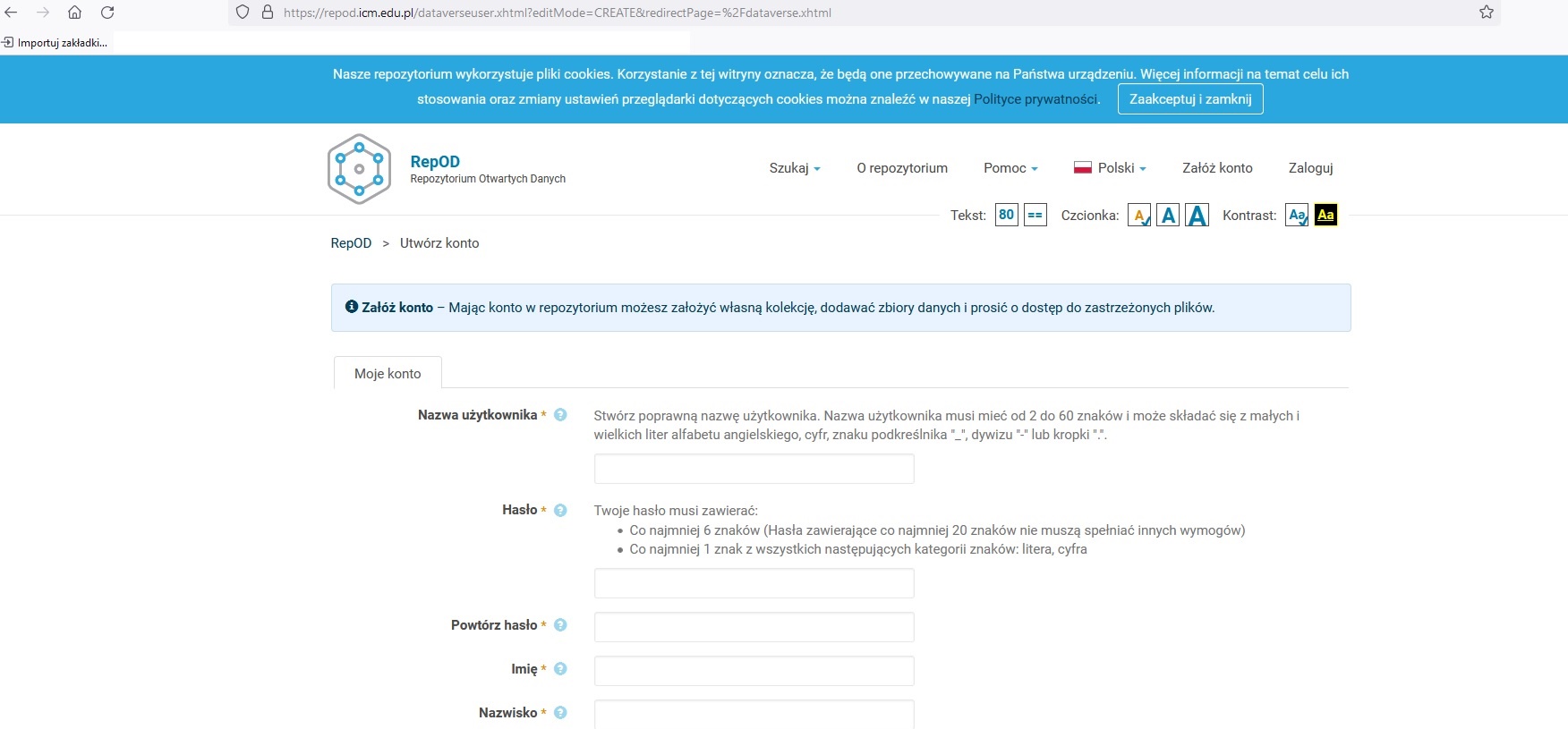
- Po utworzeniu konta na wskazany adres e-mail dostaną Państwo wiadomość z linkiem zawierający prośbę o weryfikację e-maila. Prosimy postępować wg instrukcji zawartych w tej wiadomości.
- Po pomyślnej weryfikacji można już dodawać zbiory danych.
Krok 2: wprowadzenie metadanych
- Prosimy zalogować się na swoje konto, następnie w slider wybieramy „University of Szczecin”, pokażą się wtedy zbiory danych oraz 21 kolekcji dyscyplinowych założonych dla naszego Uniwersytetu (jak pokazano na zrzutach ekranu).
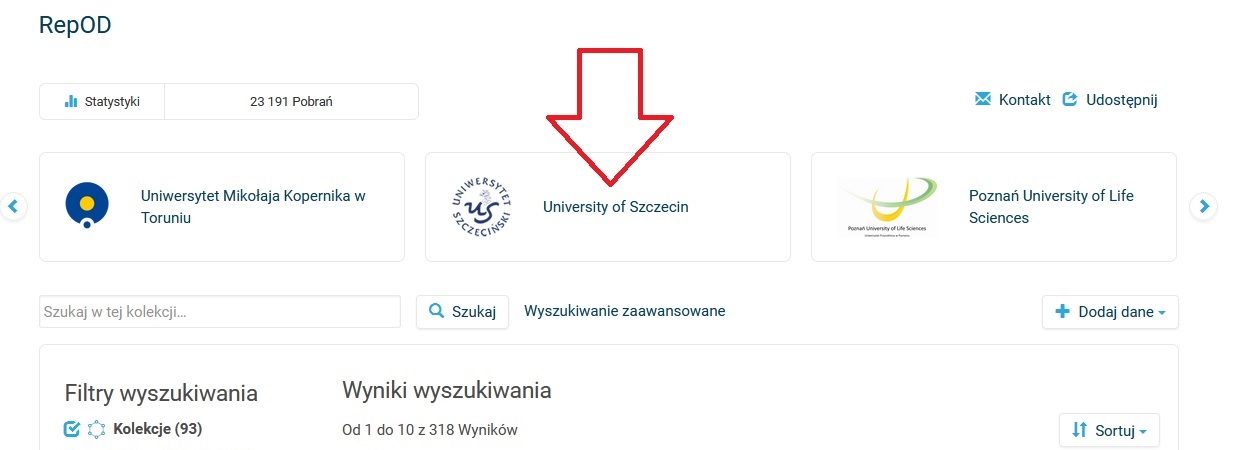
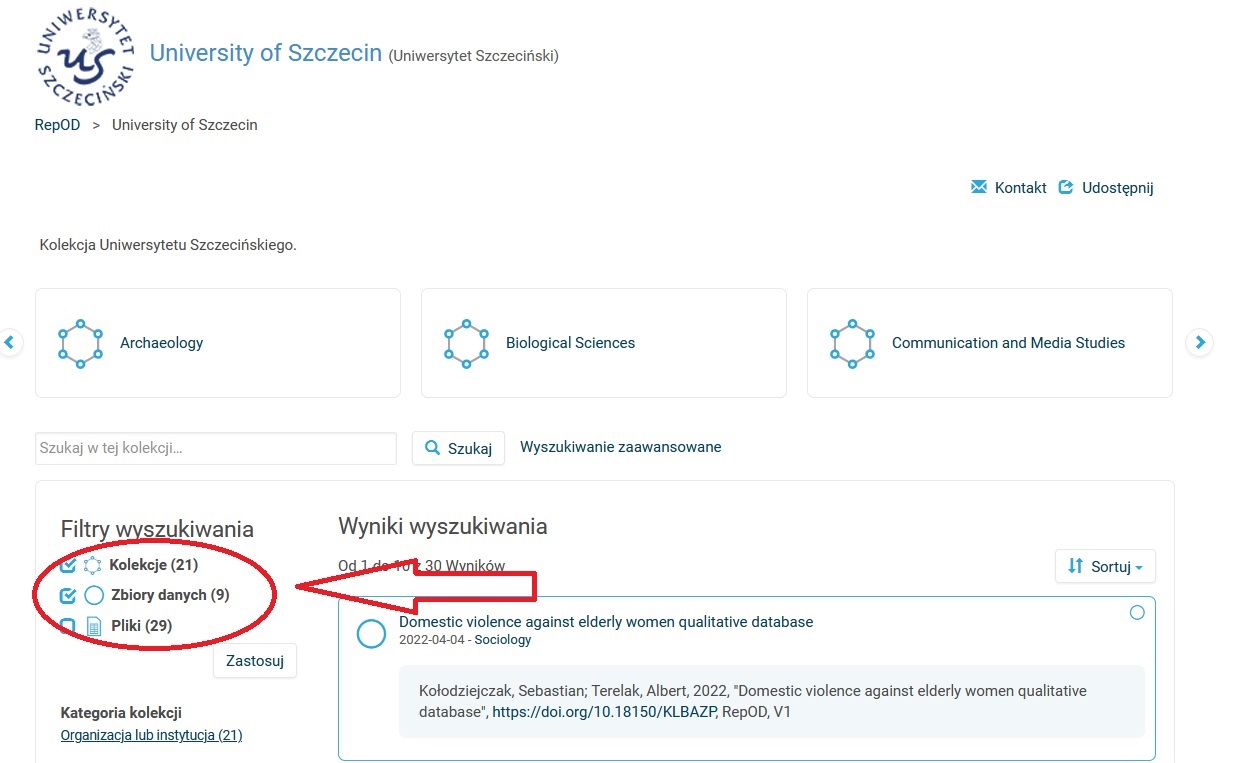
- Kolejną możliwością wejścia na stronę kolekcji jest kliknięcie w prawym górnym rogu na swoje imię i nazwisko, a następnie „Moje dane” – otworzy się lista wszystkich zbiorów danych opublikowanych w kolekcji US, a także lista kolekcji dyscyplinowych.
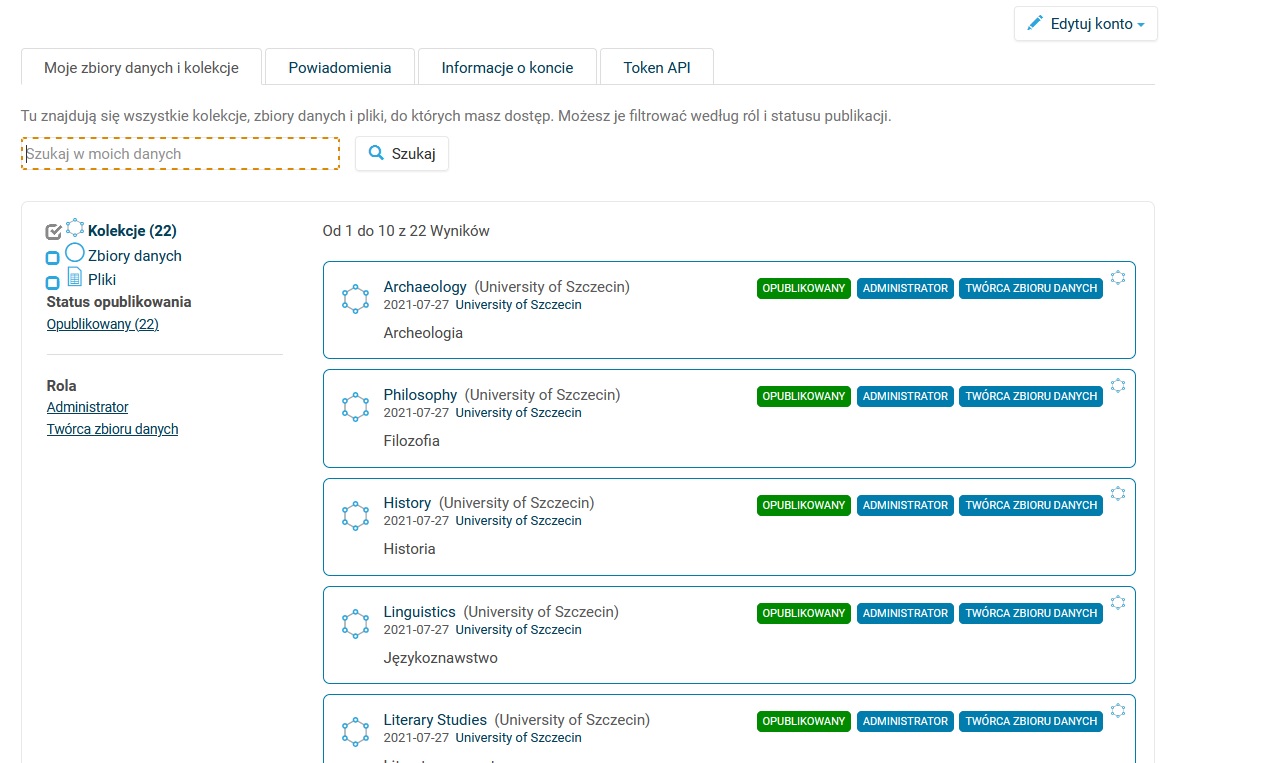
Krok 3: dodawanie plików
- Będąc na podstronie swojej dyscypliny, możemy już dodawać dane (+ Dodaj dane → Nowy zbiór danych)
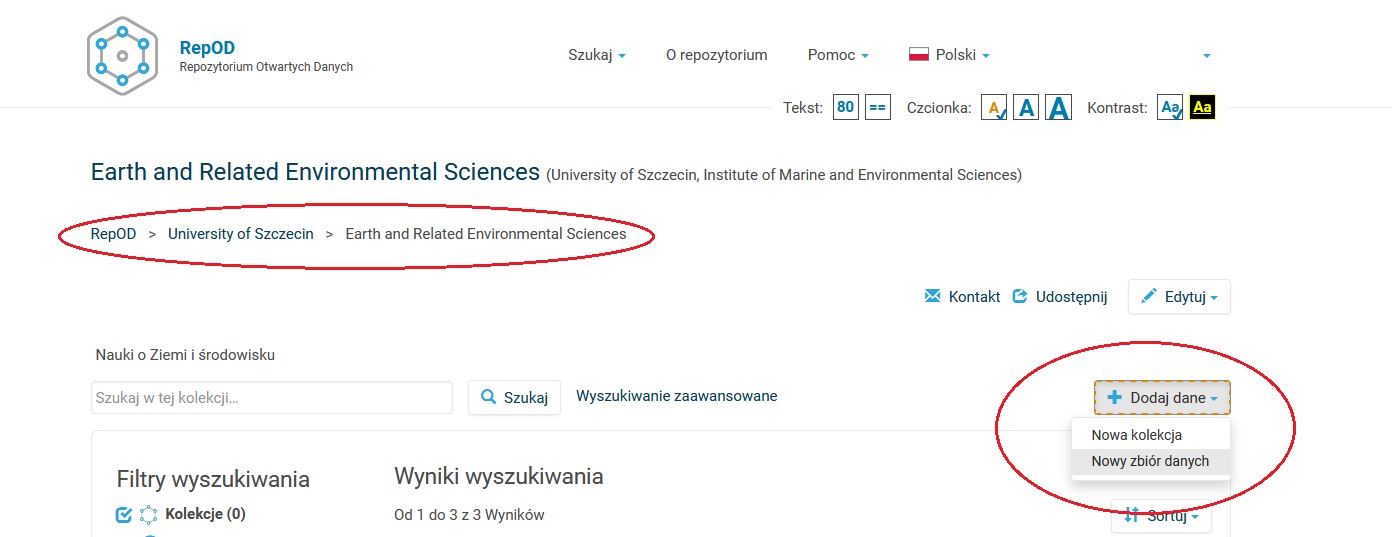
Prosimy dodawać dane bezpośrednio w kolekcji poświęconej danej dyscyplinie:
RepOD → University of Szczecin → wybrana dyscyplina.
Zakładka „Dodaj dane” widoczna jest również na stronie głównej RepOD, ale należy korzystać tylko z tej widocznej na stronie dyscypliny, inaczej zbiór danych nie będzie możliwy do odnalezienia przez administratora z naszej Uczelni.
- Wypełniamy pola dla metadanych tzn. „danych o danych”, m.in.: tytuł, imię i nazwisko oraz afiliację (wpisuje się automatycznie gdy jesteśmy zalogowani), opis, obszar tematyczny, słowa kluczowe (każde z nich w osobnym polu!), informacje o powiązanej publikacji, informacje o grancie, powiązane zbiory danych. Przy każdym okienku znajduje się niebieski znak zapytania, pod którym znajdują się wyjaśnienia, jakie dane należy w każdej rubryce wpisać.
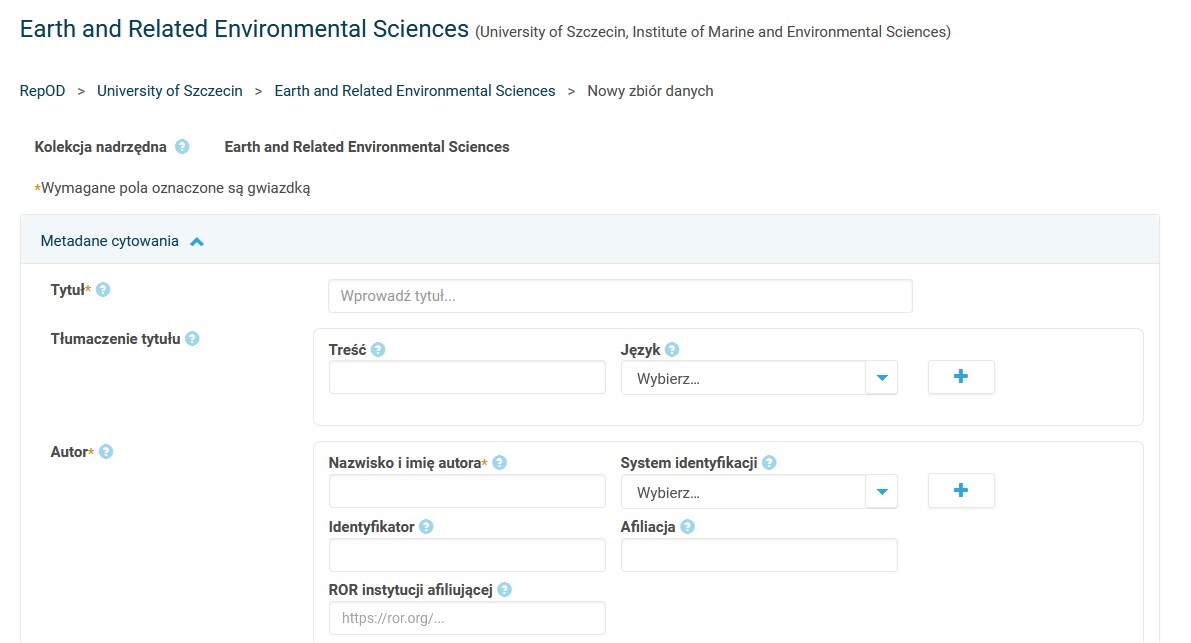
- Następnie dodajemy pliki z danymi + Wybierz pliki do dodania oraz wybieramy Zapisz zbiór danych.
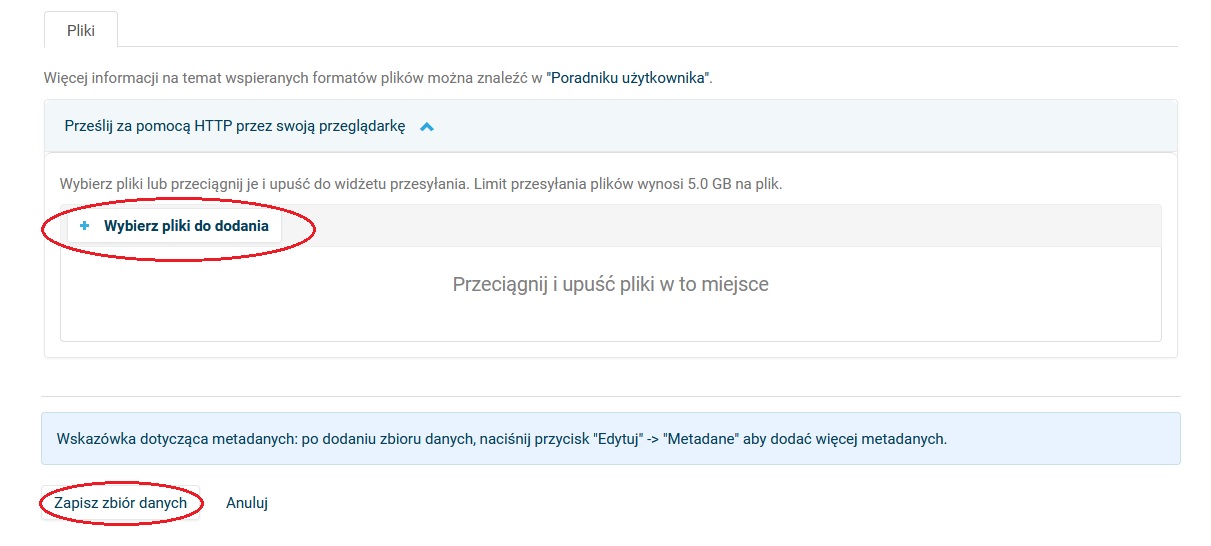
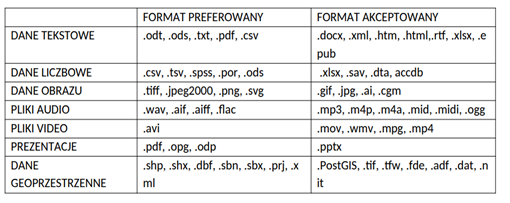
Sugerujemy zapisywanie danych w ogólnodostępnych formatach plików, łatwych do odczytania i interpretowania. Korzystanie ze standardowych i wymiennych lub otwartych formatów danych bezstratnych zapewnia długoterminową użyteczność danych. Należy wybrać formaty plików bez kompresji, nie wymagające komercyjnego oprogramowania, otwarte, z dostępną dokumentacją, wykorzystujące standardowe kodowanie (dla RepOD najlepiej UTF-8).
Krok 4: wybór licencji
- Do udostępnienia plików proponujemy wybór licencji CC BY 4.0 (Creative Commons Uznanie Autorstwa).
Krok 5: udostępnienie danych
- Dane i metadane po zapisaniu są jeszcze dostępne dla autora do sprawdzenia, poprawy, weryfikacji czy wymiany pliku. Następnie przekazujemy dane do weryfikacji (za pomocą przycisku “Przekaż do weryfikacji”) do administratora, który może je zwrócić do poprawy lub opublikować. Po ich opublikowaniu wszelkie wprowadzane zmiany są zapisywane jako nowe wersje danych.
- Osobą weryfikującą dane na US jest dr Magdalena Czyszkiewicz z Biblioteki Głównej US, tel. 91 444 2535, magdalena.czyszkiewicz@usz.edu.pl
Repozytoria na świecie:
- OPENDOAR (Directory of Open Access Repositories) – serwis zawiera listę repozytoriów realizujących założenie bezpłatnego dostępu do wiedzy oraz ideę otwartej nauki. https://v2.sherpa.ac.uk/opendoar/
- ROAR (Registry of Open Access Repositories) – spis archiwów cyfrowych z całego świata z różnych dziedzin. http://roar.eprints.org/
- OAD – serwis tworzony przez Simmons College, zawiera różne repozytoria dziedzinowe. http://oad.simmons.edu/oadwiki/Main_Page
- OpenAIRE – agregator światowych repozytoriów. https://www.openaire.eu/
- FigShare https://figshare.com/
- Zenodo https://zenodo.org/
- FAIRsharing.org – platforma indeksująca bazy danych https://fairsharing.org/new/database
- Mendeley Data – repozytorium danych które indeksuje dane z innych repozytoriów https://data.mendeley.com/faq
Polskie repozytoria:
- CeON – ogólnopolskie repozytorium naukowe https://depot.ceon.pl/
- Repozytorium ZUT – repozytorium Zachodniopomorskiego Uniwersytetu Technologicznego https://oa.zut.edu.pl/
- AMUR – repozytorium Uniwersytetu im. Adama Mickiewicza w Poznaniu https://repozytorium.amu.edu.pl/
- Most Wiedzy – repozytorium Politechniki Gdańskiej https://mostwiedzy.pl/pl/
- RUW – repozytorium Uniwersytetu Warszawskiego https://depotuw.ceon.pl/
- RUMAK – repozytorium Uniwersytetu Mikołaja Kopernika w Toruniu https://repozytorium.umk.pl/
- RUJ – repozytorium Uniwersytetu Jagiellońskiego https://ruj.uj.edu.pl/xmlui/
- Cyrena – repozytorium Politechniki Łódzkiej http://repozytorium.p.lodz.pl/
- RUWr – repozytorium Uniwersytetu Wrocławskiego https://www.repozytorium.uni.wroc.pl/dlibra
- RUB – repozytorium Uniwersytetu w Białymstoku https://repozytorium.uwb.edu.pl/jspui/
Inne wybrane repozytoria:
- arXiv – najważniejsze światowe repozytorium dla nauk ścisłych https://arxiv.org/
- RePEc (Research Papers in Economic) – repozytorium nauk ekonomicznych http://repec.org/
- COGPRINTS – archiwum z zakresu psychologii, lingwistyki, nauk kognitywnych, informatyki, filozofii, biologii http://cogprints.org/
Jak znaleźć właściwe repozytorium danych?
- re3data.org (Registry of Research Data Repositories) https://www.re3data.org/